I recently had to have my watch repaired. I brought it to the watch shop where it turned out that it could not be fixed, because a main part needed to be completely replaced, but they didn’t have any spare parts. The lady behind the counter told me that she had no idea how much time it would take to get it. It could be one week, two weeks, one month or even two months. She told me that she would give me a call when it was there. I got upset: how hard could it be to know the time they needed to bring something from A to B? Most probably they had ordered something similar before. I didn’t want to make a scene, so I let it go and asked her to order the spare part.
 After one and a half months, she finally called me, and when I was in the shop, the watchmaker told me that he would need 20 minutes to change the broken part with the ordered one. I was happier than the last time I was there, but he told me his estimation rather promptly and it was too accurate, so I got suspicious. I was watching him the whole time - so he couldn’t cheat -, and he did it in 19 minutes, so it was a good estimate. How was he able to do this? I didn’t know, so I asked him. He said that he had done this kind of task before, he had known all the possible problems, and in the worst case scenario he would have needed about 20 minutes. That’s something I’ve seen before. This is exactly what we do with our lead time distribution diagrams. So there are people out there outside of my domain using the same technique effectively - without the fancy tools we like to use.
After one and a half months, she finally called me, and when I was in the shop, the watchmaker told me that he would need 20 minutes to change the broken part with the ordered one. I was happier than the last time I was there, but he told me his estimation rather promptly and it was too accurate, so I got suspicious. I was watching him the whole time - so he couldn’t cheat -, and he did it in 19 minutes, so it was a good estimate. How was he able to do this? I didn’t know, so I asked him. He said that he had done this kind of task before, he had known all the possible problems, and in the worst case scenario he would have needed about 20 minutes. That’s something I’ve seen before. This is exactly what we do with our lead time distribution diagrams. So there are people out there outside of my domain using the same technique effectively - without the fancy tools we like to use.
I brought up this story, because last week I read Morgan Ahlström’s post titled Why my estimates don’t matter, where he concluded:
…So if predictability is what you’re looking for, don’t invest much in your estimates, instead you should make sure that your capacity is known and that quality (internal as well as external) is well understood. And that’s why your estimates don’t really matter.
If one is a service provider that might be true, but in most cases we work for somebody else, and that person, who is on the other side of the flow, wants to know when the work will be done. If I don’t or cannot tell her, I won’t get the job. She is not interested in my capacity planning or internal issues, she is not interested in half results or iterations, she wants to know when I can deliver the whole package. So people (like myself in the watch shop) want to know when they can get what they asked for, regardless of the reason why they need to know it. Therefore we cannot just stop doing estimations, because we think that they don’t matter. It matters to somebody, and it is part of the job to provide them accurately.
I assume that Morgan meant guessing instead of estimation. If this assumption is true, then he is right. What doesn’t matter is the guessing work that we tend to do under the name of estimation, because it is inaccurate. The watchmaker from my story didn’t guess. He used his current knowledge and his past experience to give me a rather accurate estimation.
There can be several explanations why we’re guessing instead of using our past experiences. Most of the cases, the “past experiences” simply don’t exist. Nobody collects them properly - or at all -, therefore people try to remember them, but unfortunately they all remember differently. After a long discussion they can find something that they remember similarly, but it seems so small, irrelevant, or useless that the guessing seems to be a better alternative.
So, if we collect data about the past, we’ll be able to provide better estimations. The best way I know to do this starts with the creation of the lead time distribution diagram:
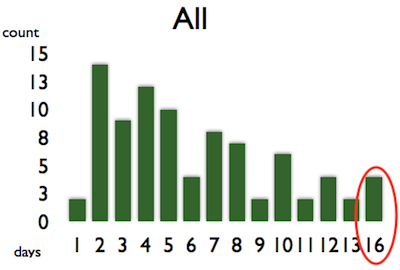
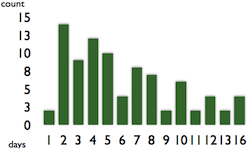
The diagram above shows the number of finished work items (the height of the bars) with their lead times. The rightmost lead time is the best estimate for your upcoming work items based on the “past experiences”. Based on the diagram above, you can decide to go with 2 days lead time, because in most of the cases the work has been done in 2 days. However, the evidence shows that there were work items with longer lead times, so taking 2 has higher risk in being late than the rightmost 16. So if you don’t want to be late, it is wise to give that time as an estimation or prediction. Sometimes that time seems unrealistic so you’d rather pick the second from the right. Before doing this, consider that this kind of data has an expiration date. The more you learn about a domain and about the technology, the less time you’ll need to finish. So instead of taking the second column from the right, filter out the old data from your diagram and take the rightmost column.
Filtering can also be applied when you are looking for the lead time for a specific kind of work item. If you know that the work item is similar to a group of already finished work items, you don’t have to work with a global distribution diagram. Simply filter out everything else and you’ll see the lead time distribution for that specific group:
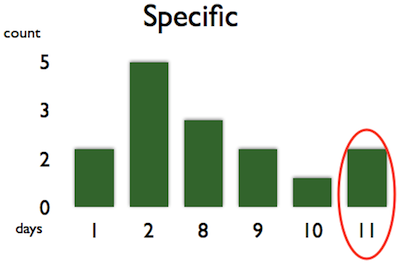
The planning meetings with my previous team took only minutes, because we were looking for these specific groups. When a new work item arrived at the horizon, we figured out which group it belonged to, and took the lead time distribution diagram of that group and picked the rightmost lead time. In order to keep our predictions accurate, in every two weeks we filtered out the old data. There was no guessing, no lengthy and exhausting planning meetings. It was highly efficient. If you want to learn more about our approach, have a look at the talk I gave at Lean Agile Scotland in 2012.
comments powered by Disqus