The other day I found myself writing a single test case the whole day without making a significant progress in the production code. It wasn’t efficient at all and I wasted the whole day on stupid test cases - so it was time to ditch TDD for the rest of the weekend and try something different. After calming down I asked myself why I was writing test cases when I didn’t have a clue about the next step. So, instead of writing tests I wrote a spike. It wasn’t nice at all, but showed me which direction I should go. I wrote a test case which tested the spike and was green, and I deleted the spike afterwards. And at this very moment, the Spike Solution from XP finally made perfect sense to me.
According to extremeprogramming.org a spike is a proof of concept: “Create spike solutions to figure out answers to tough technical or design problems”. Sounds great; it resonates well with my conclusions above (the next time it would be fantastic to find the science first and then the practice and not vise versa ;-)). And from now on - until I find something better - I’m going to follow this workflow in my projects:
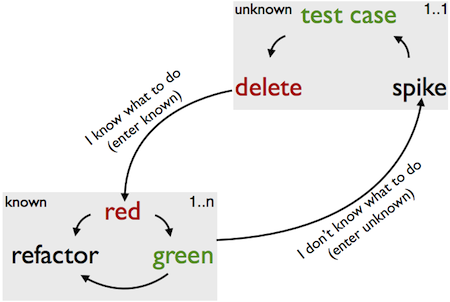
If I know what I should do I’ll use TDD, if I don’t, I’ll write a spike. When I’m satisfied with the results, I write a test case (acceptance or unit). Next I delete the spike, and inject the new test case into the TDD cycle which will be red in that context (there is no matching code, remember: the spike is gone, so it should be red).
Here is an example. I have a nice algorithm that does certain things to numbers. I know the inputs and outputs of the algorithm, so it is TDD, no questions. However, an algorithm alone is worthless. Either I need an app, a command line interface, or an API. There are too many options and possibilities, so I’d make more progress by just writing spikes until I find the right solution. When I have it, I’ll write a test, delete the spike and let TDD do its magic.
As you can see the “spike turn” takes more time, and you should be prepared for that. If you aren’t prepared enough, you’ll do the same mistakes I did. I was writing spikes for days. From a certain point of view, there is no difference in writing spike code for a day and writing test code for a day. So my agreement with myself was that I have to sweat out at least one acceptance test in a day when I’m doing a spike.
After making progress with the new workflow in my project, I realised that I ended up with a nice test pyramid:
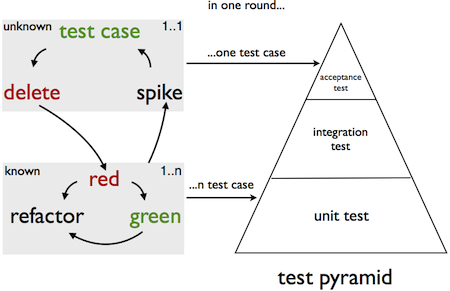
The “spike turn” produces one acceptance test case, but the TDD produces more, because the acceptance test case kind of covers the more likely scenario, whilst the unit tests cover all the possible scenarios and outcomes.
This workflow is very similar to a BDD workflow, but there are two important differences. First, BDD is a conversation tool between product and development. Second, the two parties (product and development) have an idea about how the application should behave. I’m using my main success scenario because I don’t have a clue how it should behave. Anyway, I’m happy with it, and if you give it a try, don’t forget to comment and share your experiences.
comments powered by Disqus